Scientific Libraries, Plotting
| Previous: Scientific Libraries, Statistics | Next: Last words |
Required course material for the lesson
Powerpoint: Plotting
Subjects covered
matplotlib
seaborn
Exercises to be handed in
- Generate a large number of values between 0 and 1 using NumPy and save it in a variable. Use matplotlib to plot the linear function, the quadratic function and the cubic function of the numbers. Remember to add elements to the plot that makes sense (legend, title, etc.)
- Load the file pathogen_abundance.tab in a dataframe using pandas. Show the 15 pathogens with the highest CLR-value in a plot. Remember to add plot title, axis, etc.
- To solve this exercise, you need the file resfinder_project.tsv, which you made in exercise 5 from Scientific Libraries, Pandas, Numpy. The task is to make a heatmap that displays the sum of the MIC values of the different antimicrobials for the 3 different types of organisms that are available. Hints: Groupby & Seaborn.
- Advanced plotting: Load the file Bioreactor_results.csv as a pandas dataframe and take a look at the data. Note that the numbers in the file are in English notation. The data shows two types of experiments that have been done (Replicate 1 and 2) for a number of different strains of fungi. The wild type (ATCC 1015) is also shown.
Imagine that you are a PhD student and your supervisor wants you to make a plot that shows the growth of the different strains of fungi in each experiment together in one plot.
Think about how you want to make this plot. How could you do it in a way that makes sense?
Now, take a look at the plot that your supervisor made. Try to replicate the plot using the methods that you have learned. This is more difficult than it looks like! - Return to exercise 1 last week, Scientific Libraries, Statistics. Generate 10000 datasets with 1000 data points. Set the pvalue cutoff to 0.95. This way the samples that makes the cut will be "good" normal distributed samples. In a single plot, plot all the "bad" datasets with red, the "good" datasets with green, and the best dataset (largest pvalue) with blue. It should look similar to this. Hint: gaussian_kde
-

Plot for exercise 1
-

Plot for exercise 2
-

Plot for exercise 3
-

Plot for exercise 4
-
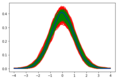
Plot for exercise 5




